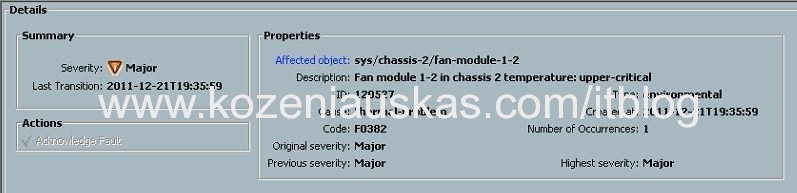
UCSM is not accessible when login into UCS cli and running show cluster extended-state command you receive the following:
ucs01-B# show cluster extended-state
Cluster Id: 0xe123456789123456-0xac12345678987456
Start time: Mon Apr 8 00:00:16 2013
Last election time: Tue Apr 22 18:50:00 2013
B: UP, SUBORDINATE, (Management services: SWITCHOVER IN PROGRESS)
A: UP, PRIMARY, (Management services: SWITCHOVER IN PROGRESS)
B: memb state UP, lead state SUBORDINATE, mgmt services state: INVALID
A: memb state UP, lead state PRIMARY, mgmt services state: INVALID
heartbeat state PRIMARY_OK
INTERNAL NETWORK INTERFACES:
eth1, UP
eth2, UP
HA NOT READY
Management services: switchover in progress on local Fabric Interconnect
Detailed state of the device selected for HA storage:
Chassis 1, serial: FOX12345678, state: active
Chassis 2, serial: FOX12345678, state: active
As we can see from the error the switchover is in progress but management services are not running on any of the FI’s so switchover cannot complete and this is the reason why you cannot access UCS Manager.
The blades running on this UCS infrastructure are not affected and should be running fine.
To fix the problem you need to reboot both Fabric Interconnects, one Fabric Interconnect at a time.
- SSH to one of the Fabric Interconnects and type:
connect local-mgmt
reboot - Wait until the fabric interconnect reboots it can take 20-30 minutes.
- Once it rebooted you should be able to open UCSM
- In UCSM verify that the fabric that was rebooted has fully came up
- SSH to the second Fabric Interconnect and reboot it
- After Fabric Interconnect is up, SSH to UCSM IP and run:
show cluster extended-state - Verify that the cluster is in good state.