So here is how to upgrade Nexus 5000 series switch. In this instance I have 2 Nexus 5010 switches in vPC configuration as they are part of the Vblock. I will be upgrading them from 5.1(3)N1(1a) to 5.2(1)N1(1)
First of all, although upgrade procedure is pretty much the same, please always check with Cisco for latest upgrade guides:
http://www.cisco.com/en/US/products/ps9670/prod_installation_guides_list.html
For the upgrade to be done as quick as possible it is important to do some work before it, like downloading the files from Cisco, uploading them to switches and running checks.
- Download Kickstart and System files from Cisco.com
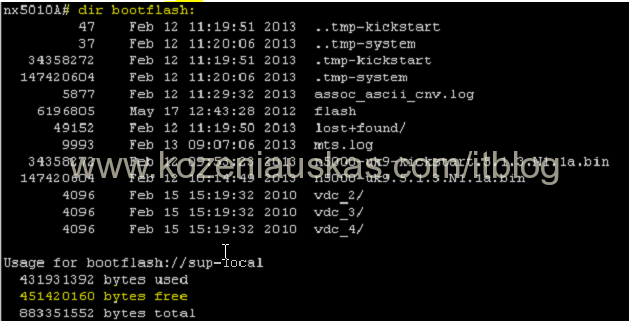
- Verify that you have enough space on the switch
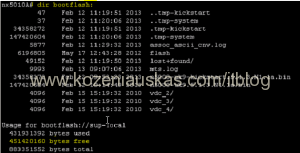
dir bootflash:
- Upload both files to the switch. In this case I used TFTP server:
copy tftp://x.x.x.x/kickstart_or_system.bin bootflash: <=== replace x.x.x.x with TFTP server IP, kickstart_or_system.bin with your Kickstart or System file name.
type management when asked to Enter vrf

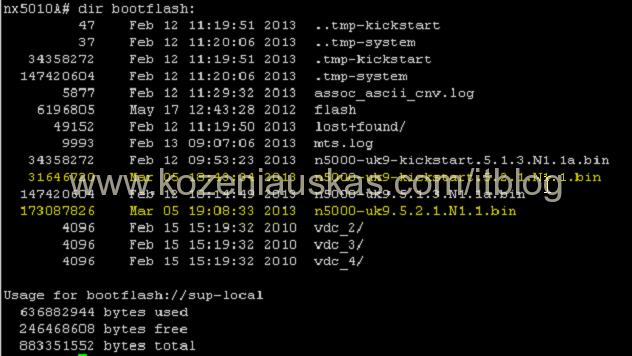
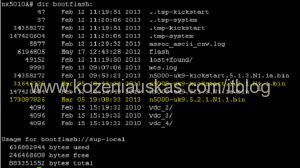
Note: In Vblock upload files to both switches. Copy operation might take some time. - Once both Kickstart and System files are uploaded verify that the file size of both files is correct.
dir bootflash:
- Now we need to run some pre upgrade checks which will show if there any problem that should be fixed before the upgrade can be started
show compatibility system bootflash:system.bin <=== replace system.bin with your System file name.
You should get No incompatible configurations message

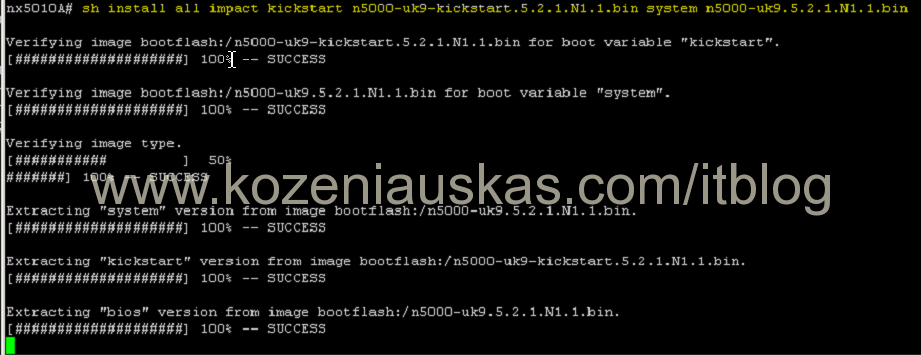
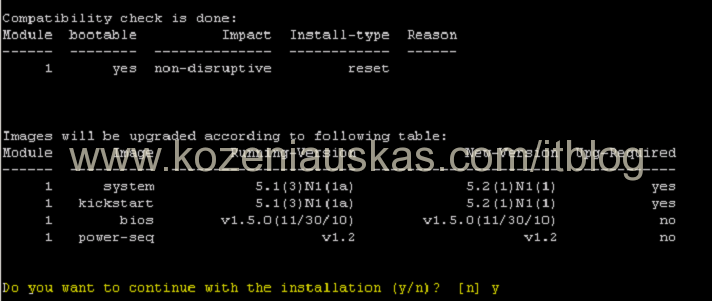
- Next we to see the impact of the upgrade:
show install all impact kickstart kickstart.bin system system.bin <=== replace kickstart.bin and system.bin with your Kickstart and System file names.
This procedure might look like a real upgrade but it only does all the checking
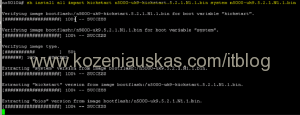
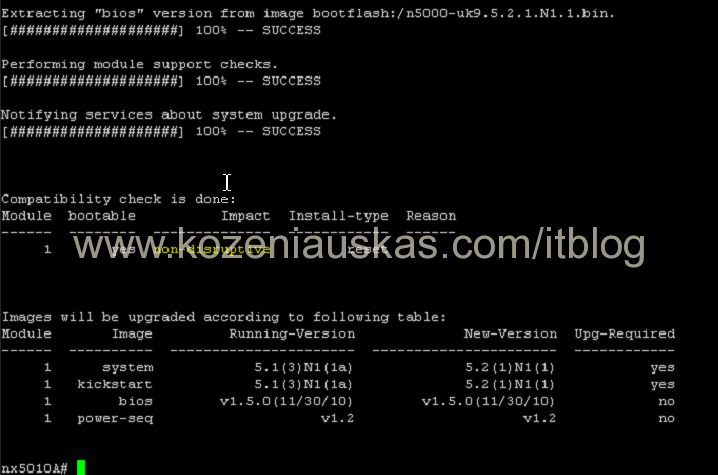
It will take some time to complete. It must succeed at all steps and should show that upgrade is non-disruptive
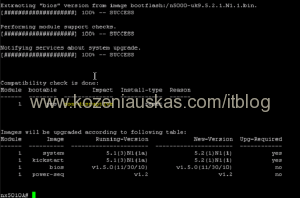
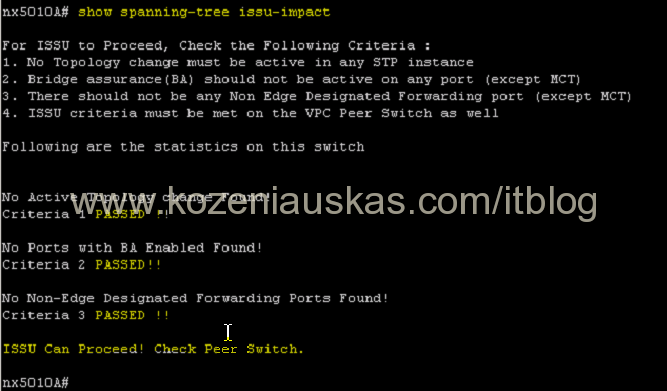
- Now check spanning-tree impact. Everything should pass
show spanning-tree issu-impact
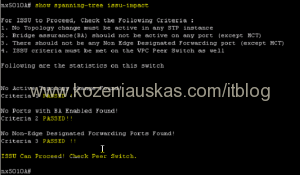
- Check lacp impact
show lacp issue-impact

- There is also show fex to verify that all fabric extenders are reachable but in the Vblock there are no extenders connected to the switches so this can be skipped.
- Once steps 1 – 9 are completed and all are OK you can proceed to upgrade.
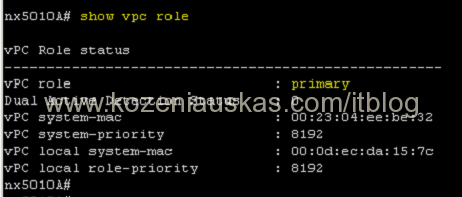
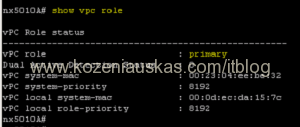
- Because this is Vblock and 2 switches are in vPC config you need to identify the primary one as the upgrade should be started from primary
show vpc role
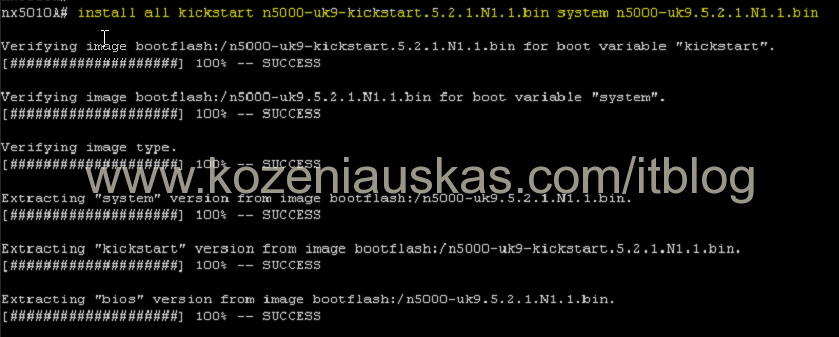
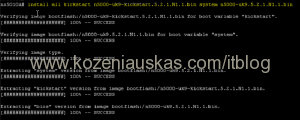
- Start upgrade
install all kickstart kickstart.bin system system.bin <=== replace kickstart.bin and system.bin with your Kickstart and System file names.
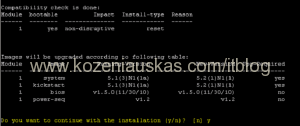
- Once prompted verify to continue by pressing y
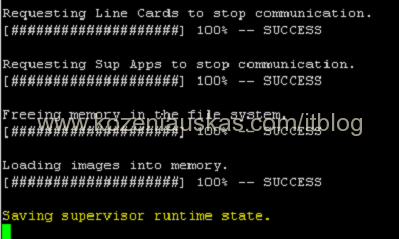
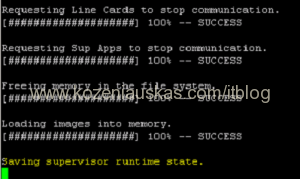
- The upgrade will begin.
If you connected to switch remotely over SSH, you will lose connectivity after seeing Saving supervisor runtime state
message as the switch is rebooting. This should take about 5 minutes. Ping it to find out when it is back online.
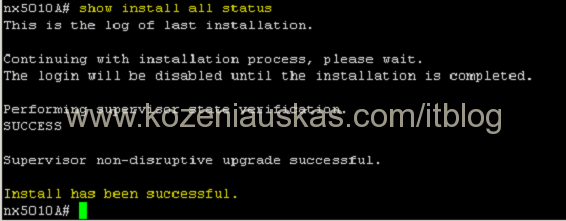
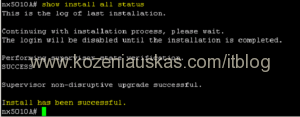
- Login to the switch and check upgrade status. If upgrade went ok you should see that it was successful.
show install all status
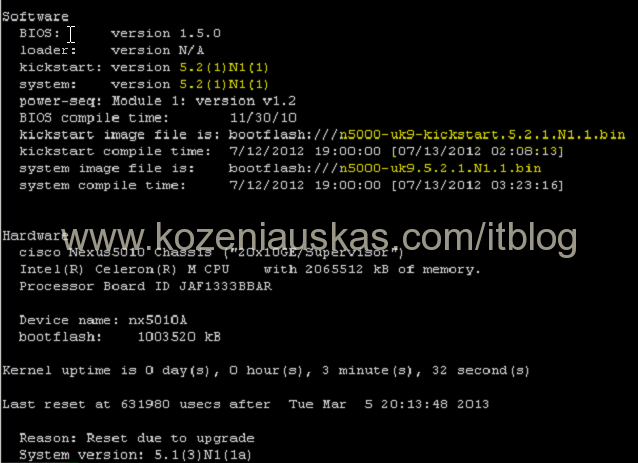
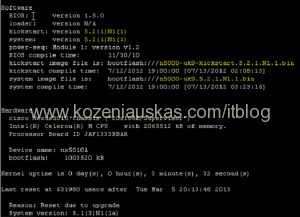
- Verify version
show version
- Verify that everything is working as expected.
Upgrade is complete - In Vblock once you’ve verified that primary switch is working fine, upgrade the secondary switch.